Обработка естественного языка: как создать «грамотного робота»


Материал подготовлен при поддержке конкурса Up Great Про//Чтение.
Уже десяток российских команд включились в сложнейшую задачу по машинному обучению. Вот её условия:Дано: реальные сочинения с ЕГЭ на двух языках — русском и английском. Их разметили школьные учителя: выделили смысловые блоки (аргументы, примеры, выводы) и нашли ошибки. В их числе — нарушение логики, искажение смысла, несоответствие теме.

Задача: создать алгоритм, который сможет размечать такие же тексты и находить ошибки не хуже учителей. То есть разметка алгоритма должна отличаться от разметок педагогов не сильнее, чем разметки педагогов отличаются друг от друга. Язык можно выбрать на своё усмотрение.
Мы пообщались с тремя командами, работающими над решением.
- «Антиплагиат» разработал одноимённый сервис обнаружения заимствований в текстах. В конкурсной команде эксперты в области машинного обучения, исследователи-алгоритмисты и специалисты по подготовке данных.
- В составе команды «Наносемантика» — сотрудники « Нейросетей Ашманова» и системы проверки правописания « ОРФО»: нейросетевики, разработчики и лингвисты.
- Команда DeepPavlov сформировалась во время работы над библиотекой разговорного AI DeepPavlov. Все участники — сотрудники лаборатории МФТИ.
Расскажите про своё решение. Какие ошибки оно уже определяет? Использовали в нём готовые модули или собственные наработки?
Антиплагиат: Делиться секретами до подведения хотя бы предварительных итогов было бы очень самонадеянно. Создание такого непростого алгоритма — задача творческая, каждая команда идёт к её решению особым путём.
Что касается результатов, то наш алгоритм приблизился к человеку в плане обнаружения грамматических ошибок.
Наносемантика: Конкурс лежит прямо в русле нашей работы. Мы развиваем одну из самых продвинутых систем проверки правописания — «ОРФО» — и как раз сейчас доделываем для неё английский граммер. А заодно экспериментируем с нейросетевыми модулями для выявления сложных ошибок — например, в расстановке артиклей, употреблении форм глагола или выборе слов из тех, которые для иностранца звучат похоже (steal вместо still или thin вместо thing).
Мы не стали ничего выдумывать, а просто попробовали подготовить бета-версию некоего продукта, напоминающего тот, который мы собираемся выпустить в будущем. Получилась в лучшем случае альфа (что тоже неплохо) — и, конечно, не хватило нескольких дней на то, чтобы выявить и исправить кучу крайне обидных ошибок. Не говоря уже о том, чтобы что-то отполировать.
Это решение не было самым простым — кажется, мы знаем, как написать примитивную заглушку, которая формально дала бы результаты получше. И не удивлюсь, если какая-то из команд в условиях цейтнота так и поступила. Но мы заметно продвинулись в тех направлениях, в которых хотели продвинуться. Судя по разметке экспертов в доступных эссе, наша модель уже исправляет артикли не хуже среднестатистического учителя. Не знаем, насколько это серьёзный комплимент.

Пример текста, который разметил алгоритм команды «Наносемантика»
На скриншоте — редкий пример текста, в котором найдено много ошибок. К другим эссе у нейросети претензий было меньше — часто одна-две, иногда ни одной. Сочинение, впрочем, действительно выдающееся: внимательный читатель, хотя бы немного знающий английский, легко найдёт в нём ошибки, которые наши модули пропустили.
Среди отмеченных ошибок, к сожалению, встречаются и ложные срабатывания. В предложении «дети предпочитают компьютерные игры обучению» нейросеть предлагает добавить местоимение (them), но тогда смысл исказится: «дети предпочитают играть в компьютерные игры, а не изучать их».
DeepPavlov: Мы использовали буквально всё, что могли, из нашей библиотеки и не только из неё. Для конкурса Alexa Prize от Amazon мы разработали DeepPavlov Agent — платформу для оркестрирования диалогов. Она отлично подошла и для этого конкурса и позволила нам совмещать несколько моделей, управлять ими и агрегировать результаты.
Пайплайн обработки эссе выглядел как переход данных от одних сервисов к другим с постепенным усложнением. Сначала мы проходили эссе набором аннотаторов — программами, которые позволили взять необходимые для нас сущности из текста. Извлечённые на этом шаге данные передавали уже более сложным моделям (мы называем их «солверы», от английского solve), которые искали конкретные ошибки. В конце данные встречал и объединял response selector, который решал, стоит ли использовать выдачу конкретного солвера или нет.
Качество пунктуации нас, скорее, не устраивает. Это связано с общим уровнем топовых моделей, который далёк от идеала, и с разницей между обычными текстами и сочинениями ЕГЭ.
На каком языке «говорит» ваш алгоритм — на русском или английском? И в целом, какой из них машинам освоить проще?
Антиплагиат: Мы решили попробовать силы и в русском, и в английском языках. Машины лучше анализируют тексты на английском. Во-первых, это аналитический язык (в отличие от синтетического русского), что упрощает грамматический разбор предложения. Во-вторых, для работы с ним создано большое количество инструментов и библиотек, проведено очень много исследований.
С другой стороны, российским школам русский язык всё же нужен больше, да и у нас есть экспертные знания о работе с ним.
Наносемантика: Если речь о работе с текстами вообще (в том числе с ученическими), то для английского языка решения, вероятно, появятся быстрее — в мире на него тратится гораздо больше усилий. С другой стороны, он сложнее: в нём бешеная омонимия частей речи — почти любое слово может быть и существительным, и глаголом, и чем-то ещё.
Что касается конкурса, то решить задачу для английского языка проще сразу по нескольким причинам. Во-первых, там всего один тип эссе, нет деления на предметы с разными критериями оценки и типами ошибок. Во-вторых, больше доля языковых ошибок и меньше доля «фактографии». Учитель может разметить утверждение «художники ленивы» как фактическую ошибку, но такого немного, это не история с обществознанием. И сами ошибки более грубые — а значит, их легче ловить.
DeepPavlov: На английском. Для него сейчас больше моделей и корпусов. Русский язык сложнее с лингвистической точки зрения, и для работы с ним доступно гораздо меньше данных — алгоритм для него наверняка получился бы у нас хуже.
Кроме того, согласно конкурсным требованиям, алгоритм для русского языка должен давать решения сразу для четырёх школьных предметов. Сложность была бы, например, в обществознании — из-за нечёткости и «зыбкости» самого предмета и неоднозначности формулировки задачи.
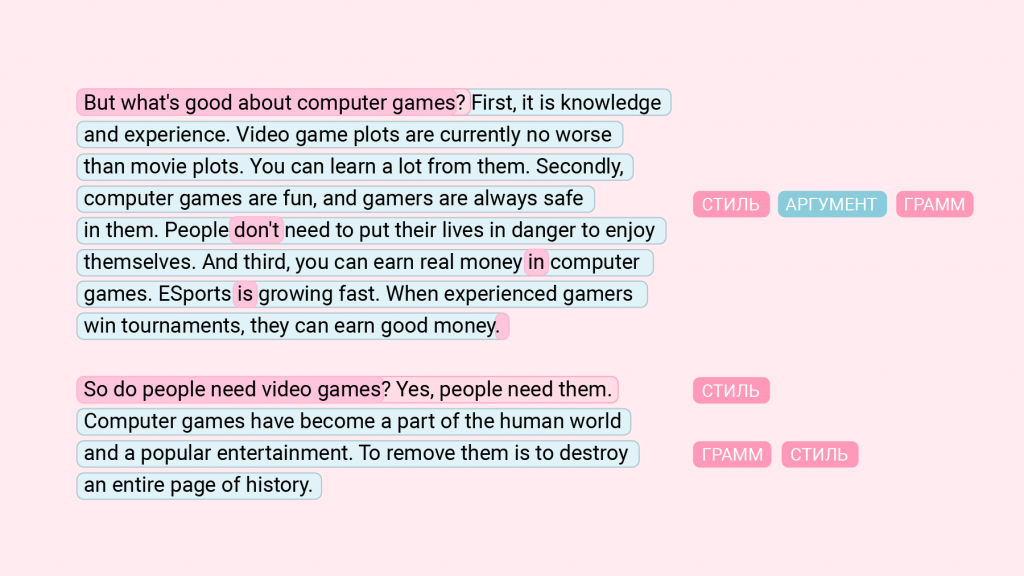
Пример текста, который разметил алгоритм команды DeepPavlov
И матерные слова знает?
Антиплагиат: В соответствии с конкурсной задачей алгоритм должен справляться и с поиском этических ошибок — бранных слов, вульгаризмов, жаргонизмов, арго.
Однако мы подошли к этому прагматичнее: в материалах для обучения не было ни одной ошибки, связанной с матерными словами, поэтому решили на этом этапе их пропускать.
Наносемантика: Разумеется. Научили уже много лет назад. Правда, для конкурса пока не пригодилось.
DeepPavlov: У нас был компонент из другой модели, как раз определявший матерные слова как элемент разговорного стиля. Но мы его заглушили из-за специфики датасетов: в текстах ЕГЭ таких слов не было.
Пришлось пообщаться с лингвистами или учителями для понимания задачи?
Антиплагиат: Лингвистов в нашей команде нет, с педагогами удалось пообщаться на старте конкурса — разобрались, как оценивают сочинения на ЕГЭ. Скорее из любопытства: для большинства из нас это было в новинку, но освоиться можно было и самим.
Наносемантика: Среди нас есть лингвисты. Учителей не привлекали, но разбираться с тем, что они «подчёркивают красным», пришлось. Дело в том, что по условиям конкурса ошибка, которую алгоритм отметил, а проверяющие нет, — большое зло, даже если это действительно ошибка. Она влияет на результат ровно так же, как ошибка, отмеченная учителями, но «пропущенная» алгоритмом.
DeepPavlov: Учителей к проверке не привлекали, а лингвист по образованию в команде уже есть. Посчитали, что справимся с этой задачей не хуже — для её решения не нужно входить в десятку топовых специалистов по языку. В критерии проверки ЕГЭ долго и упорно вникали сами, скачали подборку проверенных эссе например.
Был ли момент, когда ваш алгоритм сделал рывок и вы подумали про себя «вау»?
Антиплагиат: Пока рано об этом говорить — по ощущениям мы пока только «въезжаем» в конкурс, разбираемся в его особенностях.
Наносемантика: У нас была модель, которая больше недели под разными предлогами отказывалась появляться на свет. Ранним утром перед конкурсом она, наконец, «сварилась». Экспресс-тестирование показало, что эта модель действительно ловит больше ошибок, чем предыдущая.
Потом оказалось, что из-за дурацкой описки в коде модель примерно в трети случаев хоть и находила ошибку, но не давала правильного исправления и указывала случайные тип и подтип.
DeepPavlov: Таких «вау» было много, но на одно «вау» в среднем было пять «Как так? Почему он это не находит?». Среди примеров были моменты, когда мы собирали всё в единый пайплайн и оно наконец начинало работать и не мешать друг другу. И частота таких «вау» к концу соревнования постоянно увеличивалась.
Сейчас можно автоматически сгенерировать связный текст и даже новостные заметки. Почему с проверкой текста всё резко становится сложнее?
Антиплагиат: Генерация связного текста — куда более простая задача, чем создание «электронного учителя», такие алгоритмы существуют уже несколько десятилетий. У нас есть даже тестовое задание для тех, кто приходит на наши вакансии, — написать генератор связного текста. В последнее время в этом направлении исследователи продвинулись очень хорошо, но даже современным алгоритмам пока не удаётся уверенно проходить тест Тьюринга.
Наносемантика: Не последнюю роль играет эффект «Неуловимого Джо»: если бы эта задача была более востребованной, она была бы уже решена — по крайней мере, гораздо лучше, чем сейчас.
Есть и объективные трудности. Например, гораздо проще распознать, что в тексте что-то не так, чем предложить правильное исправление. Это хорошо видно по самым продвинутым системам проверки правописания.
DeepPavlov: Механизмы генерации текста и исправления ошибок отличаются. Разберём на примере модели GPT-2, компоненты которой мы пробовали. Для генерации текста подобные алгоритмы выбирают наиболее популярные сочетания слов. Если дать им отредактировать текст, то они исправят все фразы на наиболее часто употребляемые.
Это самая сложная задача, с которой сталкивалась ваша команда? Какие ощущения от мысли, что её пока не удалось решить никому?
Антиплагиат: Не первая амбициозная задача в нашей практике. К примеру, один из наших алгоритмов распознаёт, что автор взял фрагмент текста на другом языке, перевёл его и пытается выдать за свою мысль. Такого никто в мире ещё не сделал.
На наш взгляд, в этом конкурсе самыми сложными являются логические и фактические ошибки. Проверка связи слов и предложений — сама по себе задача непростая. Ещё больше её усложняет то, что у каждого проверяющего своя точка зрения на внутреннюю логику текста.
С фактическими ошибками ещё сложнее. Многие факты мы знаем с детства и даже не задумываемся об их происхождении. А вот алгоритму нужны огромные базы знаний, чтобы обработать такие факты — на наполнение баз потребуются тысячи человеко-лет или огромные вычислительные ресурсы.

Пример текста, который разметил алгоритм команды «Антиплагиат»
Наносемантика: Мы много разных задач решали, самую сложную определить трудно. Лингвистические задачи имеют фрактальную природу, дерево может оказаться сложнее леса, ветвь — сложнее дерева, не говоря уже о системе жилок у центрального лепестка.
Для нас конкурс — большая удача. И не только потому, что его можно выиграть — в этом раунде мы своими результатами пока не слишком довольны. А прежде всего потому, что он даёт нам замечательные данные, исключительно полезные для решения наших основных задач. Мы уже давно коллекционируем нетривиальные ошибки в русских и английских текстах, и такой богатый материал, к тому же уже кем-то размеченный, попадается редко.
DeepPavlov: Сложность задачи можно понять по формулировке, а она тянет практически на Нобелевскую премию: «Давайте сделаем лучше, чем человек». Усложнила вызов и неизвестность — было неясно, что значит «лучше», с каким человеком сравнивать и в каких условиях проводить эксперимент.
Если в качестве примера взять квалифицированного проверяющего ЕГЭ, то есть ощущение, что задача решаема. Системы способны выйти на примерно такой же уровень в проверке простых заданий.
Команды решают задачу в рамках конкурса Up Great Про//Чтение и претендуют на 100 миллионов рублей призового фонда за систему для анализа текста на русском языке. И столько же — за алгоритм для английского. Регистрация на новый цикл конкурса открыта, участникам можно составить конкуренцию — все подробности по ссылке.
















 сегодня провели очередной этап конкурса грузовых беспилотников.")


