Сможет ли искусственный интеллект понять Достоевского?


Одной из первых систем, понимающих естественный язык, была SHRLDU, разработанная в начале 1970-х годов. В ней пользователь управлял перемещением нарисованных объектов с помощью текстовых команд. Функциональность системы была очень скромной, она понимала ограниченный набор вопросов и команд. Для своего времени это был прорыв, но в XXI веке общество сформировало запрос на технологии совершенно другого уровня. Конкурс Up Great ПРО//ЧТЕНИЕ конкретизирует этот вызов, создавая новые подходы к искусственному интеллекту и глубокому пониманию письменной речи.

Современные алгоритмы понимания естественного языка — Natural Language Understanding (NLU) — работают на основе анализа корреляций и статистических данных. Машина анализирует огромный объём данных, которые собраны в готовые блоки в разных категориях, находит в них по ключевым словам совпадения и даёт ответ на основании проделанного анализа.
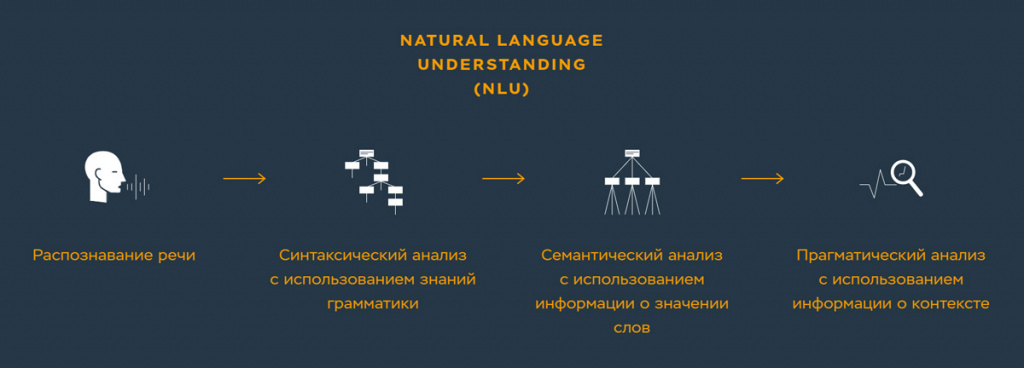
Такой подход позволяет отвечать лишь на определённые вопросы, которые машина уже проанализировала. Поэтому, когда мы обращаемся к голосовым помощникам с нестандартным диалогом, они отвечают, что ещё учатся, или отшучиваются:

Однако прогресс не стоит на месте. Разработчики пытаются научить нейросети понимать язык на более глубинном уровне, выявлять причинно-следственные связи, писать и говорить естественным языком человека на разные темы.
Для определения уровня их прогресса определяются технологические барьеры и формируются тестовые задачи, показывающие, работает алгоритм или нет.
По словам Юрия Молодых, директора по развитию технологических конкурсов Up Great в РВК, скорость развития технологий искусственного интеллекта высокая, и по аналогии с распознаванием изображений, в которых в 2010-ые годы роль катализатора сыграл конкурс ImageNet, в области естественных языков стали появляться аналогичные тестирования.
Один из примеров — созданный в 2018 году компанией DeepMind (принадлежит Alphabet) тест GLUE. Для решения этого теста DeepMind вместе с рядом технологических университетов разработала алгоритм BERT. Он может отвечать на вопросы, заданные в произвольной форме, создавать чат-боты и переводчики.

В 2019 году подразделение Facebook, занимающееся искусственным интеллектом, запустило более сложное тестирование алгоритмов — SuperGLUE, которое в начале 2020 года было переведено на русский язык. К нему проявили интерес специалисты AGI NLP из Сбербанка, лаборатория Huawei Noah's Ark, а также факультет компьютерных наук ВШЭ. В блоге Сбербанка основной целью проекта Russian SuperGLUE названо «продолжение развития русских моделей для общей задачи General Language Understanding». Созданный в рамках SuperGLUE алгоритм RoBERTA пытается находить причинно-следственные связи в тексте, что подразумевает более глубокий анализ.
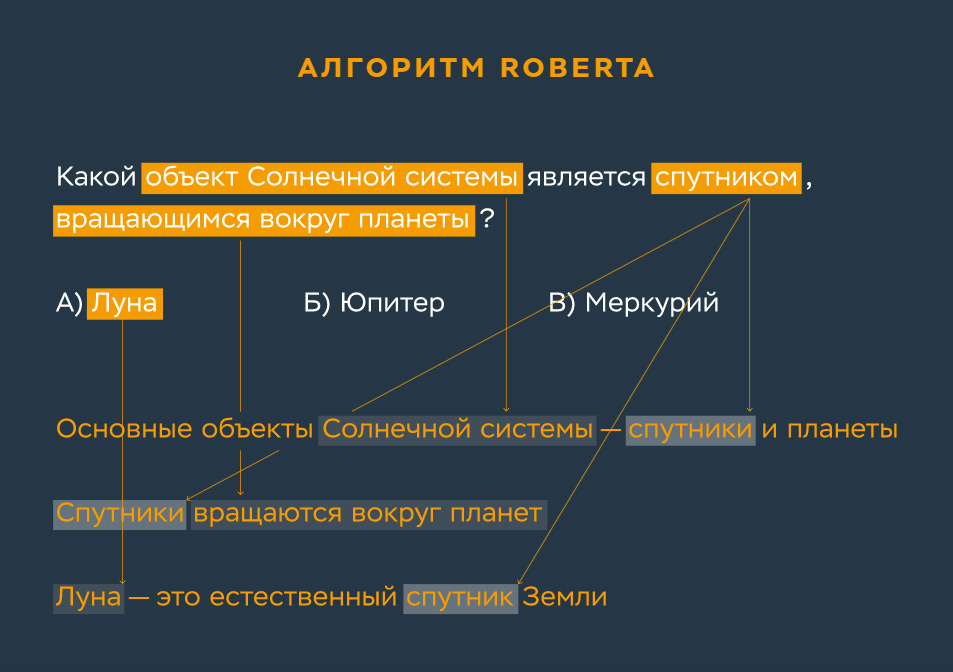
В этих тестированиях задача облегчалась тем, что машине предоставлялись варианты ответов. Такой подход имеет практическую значимость и оправдан для Facebook, которому важно решать практические задачи по улучшению сервиса. Например, чтобы понимать, какой пост показать конкретному пользователю в ленте следующим: про политику или про технологии. Но это не универсальное решение.
Для глубокого понимания естественного языка человека, считает Иван Ямщиков, AI-евангелист компании ABBYY, ещё много предстоит сделать. По его словам, существует много примеров качественных диалоговых систем, но и не меньше примеров, где они не справляются. Машинное обучение сейчас развивается как экспериментальная наука. Поэтому конкурс ПРО//ЧТЕНИЕ — о той области, где технологии ещё не развиты в достаточной степени, чтобы сформировать конечное решение задачи, но которая способна дать старт реализации прорывных проектов.
Ямщиков также обращает внимание на фундаментальные вызовы, стоящие перед разработчиками: современные модели плохо понимают, как человек выстраивает нарратив, сюжет повествования.
Кроме того, по мнению эксперта, человеческий язык является фактором социальной демаркации, и в этих тонкостях нейросетям тоже предстоит разобраться. Например, стену между израильтянами и арабами в произраильских СМИ называют security fence — «ограждение для безопасности». А в проарабских — apartheid wall, или «стена апартеида». ИИ должен учитывать, что в обоих случаях речь идёт об одном и том же объекте. Прогресс в области нейросетей привёл к появлению технологий, которые способны выстроить более глубокие взаимосвязи в человеческом тексте.

Задача участников конкурса ПРО//ЧТЕНИЕ — создать систему, которая выявит смысловые ошибки в эссе: например, недостаточное раскрытие темы или нелогичные утверждения. И затем объяснит автору сочинения, школьнику или студенту свою позицию доступным языком.
На сайте конкурса размещены первые наборы текстовых эссе на русском и английском языках. Они разделены на два типа выборок: «неразмеченная» и «обучающая». Неразмеченная выборка содержит эссе в исходном виде, без правок. А обучающая — это набор текстов, проверенных несколькими преподавателями, которые с помощью специального языка разметки выделили и объяснили ошибки.
На обучающей выборке ИИ должен научиться проверять и наносить разметку в работы, а затем сделать её на неразмеченных эссе не хуже экспертов. Тексты содержат неограниченный набор тем по русскому языку и литературе, истории и обществознанию. В течение всего срока проведения конкурса планируется увеличить тестовый набор данных до 20 тысяч текстов. А в дальнейшем, объясняет Юрий Молодых, планируется запустить общедоступный сервис со встроенным классификатором ошибок по нескольким предметам, куда каждый ученик сможет загружать свои работы для проверки ИИ. Этот сервис ляжет в основу источника больших данных, на которых в дальнейшем сможет обучаться искусственный интеллект.
Конкурс разделён на несколько циклов, каждый из которых состоит из квалификационных и финальных испытаний. Первый цикл планируется завершить к концу 2020 года. Испытания будут проходить регулярно до тех пор, пока одна из команд не преодолеет технологический барьер.
Конкурс состоит из двух видов соревнования: для русскоязычных и англоязычных эссе. Победители получат по 100 миллионов рублей в этих двух языковых категориях.
Если технологический барьер конкурса будет взят, учителя получат ультрасовременный цифровой сервис, который позволит им снизить нагрузку рутинных проверок. А у школьников и студентов может появиться свой собственный ИИ-репетитор. По сути, они получат постоянный доступ к услугам электронного тренажёра, который поможет им развивать логику, критическое мышление и учиться грамотно и логично излагать свои мысли на русском и английском языках. При этом ИИ сможет указать и на системные ошибки в том случае, если тема недостаточно полно раскрыта, есть логические ошибки или выводы не следуют из аргументов. Он также обратит внимание на неуместные сравнения и фактические ошибки.

В 2019 году технологии ИИ снова вошли в список ключевых технологических трендов. Суммарно они привлекли более одного миллиарда долларов глобальных инвестиций, и, по прогнозам аналитиков Frost&Sullivan, к 2022 году рынок искусственного интеллекта вырастет в 10 раз. Это произойдёт в том числе за счёт применения технологий машинного обучения и распознавания естественного языка в рекламе, розничной торговле, финансах и здравоохранении.
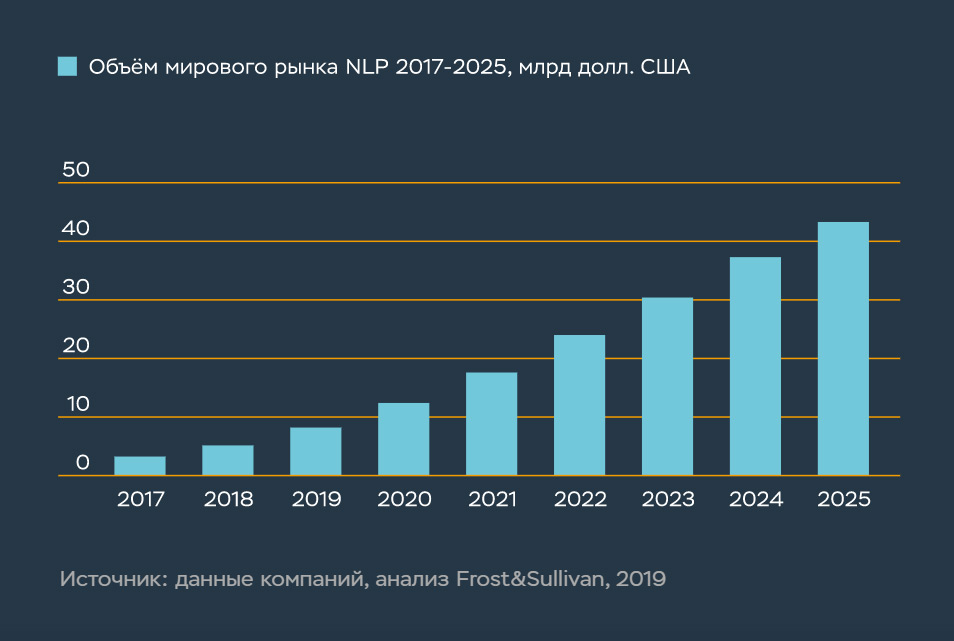
Ожидается, что мировой рынок обработки естественного языка (NLP) и продуктов на его основе к 2025 году вырастет до 40 миллиардов долларов. Этому будет способствовать растущий спрос на более качественный пользовательский опыт, увеличение пользования умными устройствами, а также применение сетевых и облачных бизнес-приложений и M2M-технологий.
Перспективные отрасли привлекают талантливых специалистов, а конкурсы помогают им реализовать свой потенциал и выйти на новый технологический уровень. За полгода на участие в конкурсе ПРО//ЧТЕНИЕ поступило около сотни заявок. Как технологический барьер конкурса соотносится с задачами реальной экономики и с потенциалом, который уже наработан разработчиками, рассказывают участники конкурса.
















 сегодня провели очередной этап конкурса грузовых беспилотников.")


